GDDR について
もともとGPGPUはGPUであり、GPUはグラフィックスボードであります。
グラフィックスボードは、DVIとかHDMIとかDisplayPort を備え、60fps などで毎フレーム画像を生成&出力するものですが、そうするとゲームなどではその fps に対して、例えば 60fps であれば 16.6ms の時間で読みだせる分量だけのテクスチャなどを絵作りに使えることになります。昨今ではマルチパスレンダリングも当たり前に行われていますので、1枚の絵を作るためにメモリ上での描画作業は何度も繰り返されます。
つまり1枚の絵を、より高精細で複雑にしようとするととにもかくにも大量のバス帯域が無いとはじまりません。
逆に、1フレーム時間で読みだせない容量があっても、それは別のシーンの描画の為の準備的なデータを置いておくことにしか使えませんので、やはり容量より帯域が優先されがちです。
そのような GPU にとって、DDR4-SDRAM のように増設できて大容量のメモリよりも、「直結必須で増設も出来ないし容量も少なめだけどとにかく速い」という GDDR は適していたのではないかと思います。
GPGPU になって
このとても速いメモリをもった GPU ですが、GPGPUになって、ご承知の通り AI などの演算に大いに活用されるようになりました。
一方で、グラフィックスとは異なる意味で容量への要求がどんどん高まり、非常に大容量のGDDRを搭載しはじめ、HPC用ではHBMを積むものも現れ始めました。
ホストメモリとは別にGPGPUにメモリがあることで課題となるのが、ホストCPU のメモリとGPGPU側のメモリの間のコピーやデータ配置です。
CUDA が出始めの頃は、cudaMemcpy API を使って、ホストからデバイスへデータコピーして、GPGPU に計算してもらい、終わったらまたホストメモリにコピーするというやり方しかなく、十分に纏まった量の計算をオフロードしないと、「計算は速いけどコピーが遅くて、ホストで計算した方が速い」なんてことも起こっていました(そして今でもパソコンのPCIeに1枚だけGPGPUカードを挿す場合などはさして事情は変わっていません)。
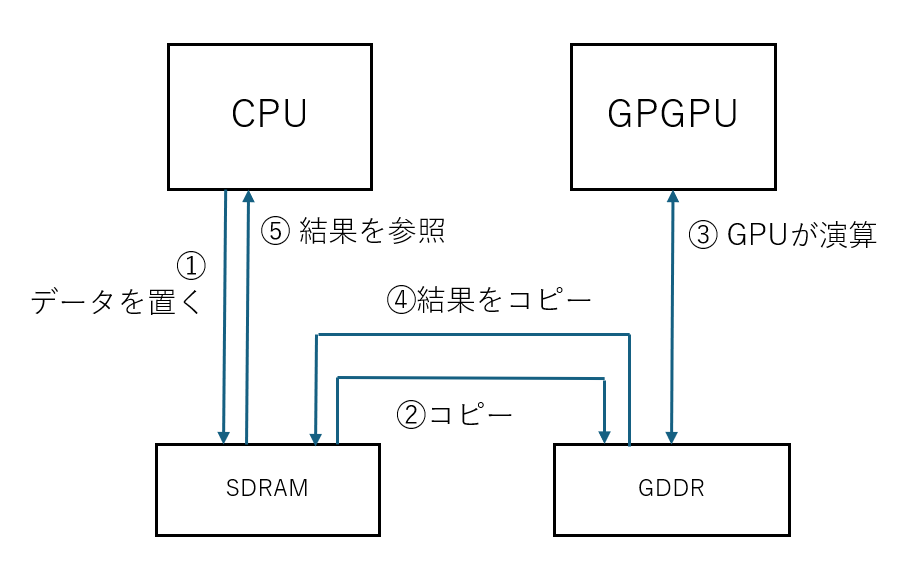
しかしながら一度コピーしてしまえば、ホスト側のメモリ帯域を消費することなく GPGPU側に閉じて、高速なGDDR上で演算が進むのは大きなアドバンテージでありました。
ホストCPUとGPGPUで別々にメモリを持つという事は、総帯域としては単純に足し算ですので、相互転送の頻度さえ抑えられる計算であれば高い性能が期待できます。
cudaMallocManaged について
これはハードウェア的なユニファイドメモリとは意味が違うと思っているのですが、ある段階で CUDA に cudaMallocManaged でメモリ確保する、ユニファイドメモリという呼び名の機構が登場したので触れておきます。
これは プログラミングモデルとして、ホストメモリとデバイスメモリを意識せずにプログラミングできるようにしたもので、少なくとも当初はアクセス時に裏で自動でメモリコピーが起こるだけという(スワップメモリと同じ仕組み)、転送量というハードウェア性能的には何も変わらない代物だったかと思います。
一方で、このモデルは将来性という点で、
- ハードウェア的に相互のメモリに乗りいれてバスマスタになれる場合
- ホストとGPUで本当に1つのメモリをシェアする本物のユニファイドメモリの場合
などにも親和性が高く、以降の拡張性を確保した仕組みの一つだったように思います。
ハードウェア的なユニファイドメモリ
Apple の M1 などからハードウェア的な意味でのユニファイドメモリという言葉をよく聞くようになった気がします。
ユニファイドメモリは同じメモリに対してCPUもGPUも同じようにアクセスできますので、先に述べたメモリコピーが発生しません。
ですので、先に上げた「計算は速いけどコピーが遅くて、ホストで計算した方が速い」なんてことは原理的に起こりえず、理屈上、CPUよりGPUが適した処理であれば、すべてGPUにオフロードできる効果が出せるはずです。
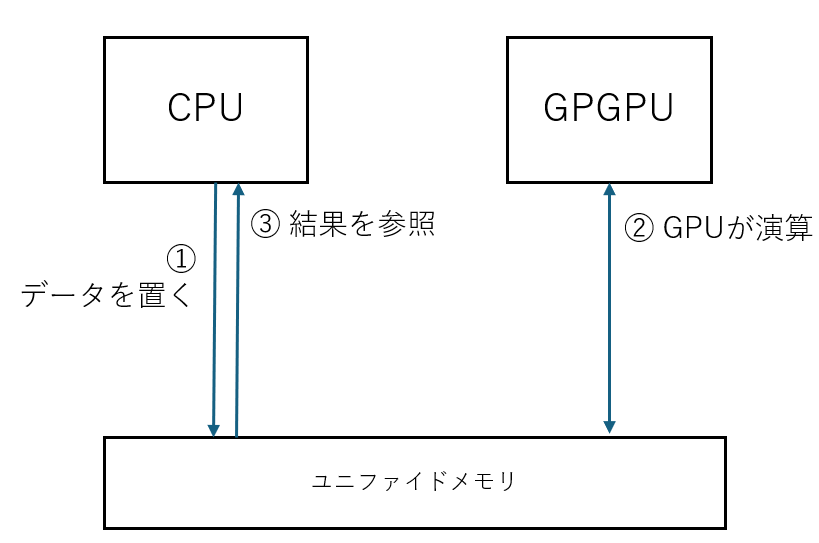
一方で、CPUとGPGPUで同じメモリ帯域の食い合いを起こしてしまいますので必ずしも良いことづくめではないかとは思います。
バスの相互乗り入れ
PCIe や NVLink のようなバスを介したり、Infiniband のような通信を介したり、あらゆる手段で別のデバイスが持っているメモリを直接アクセスできるようにするというのは一つのアイデアです。
従来であれば、自分のもつメモリにコピー(読み出し&書き込み)してもらって完了後に読みだしていたのが、直接読めるわけですからコピーコストはそこそこ抑制しつつ、それぞれのデバイスが自分の計算特性にあったコスパの良いメモリを持ちうことが出来ます。
これはこれで一つの解だとは思います。一種の ccNUMA かと思います。
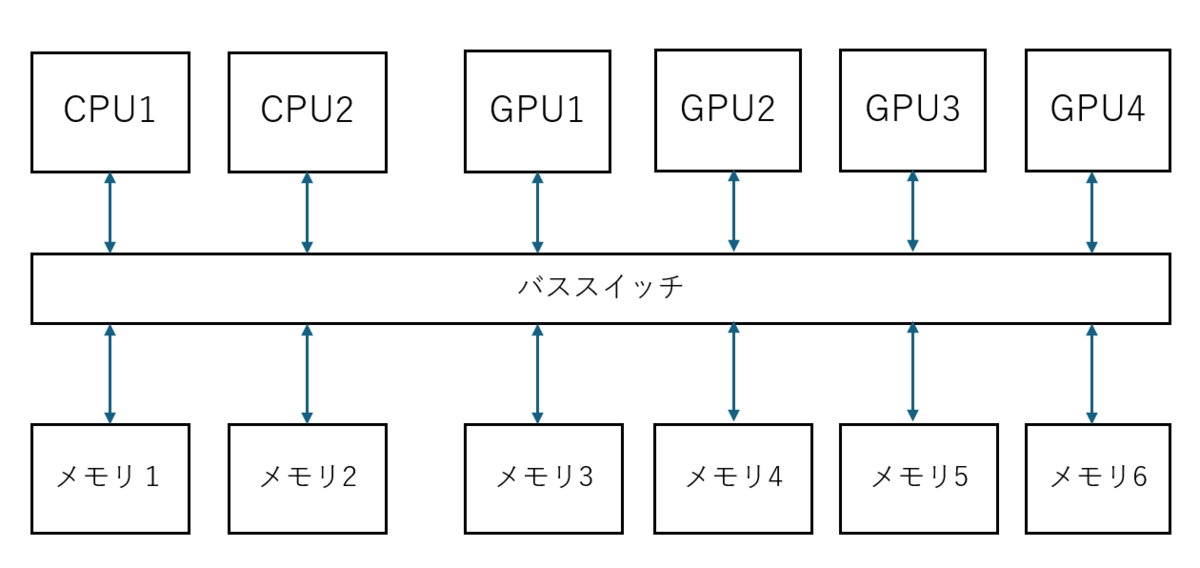
しかしながら、欠点もあり
- ノード数が増えると、メモリコヒーレンシをとるスイッチなどの規模が増大していく
- どこにデータを配置してどこで計算するかによって性能が大きく変わりうる
ということになります。
しかしながらこれらの欠点があっても、もはやプロセッサもメモリも「並列化することでしか性能が上げられない」となってきているので、結局プログラミングモデルをシンプルにしようとするとこうしかならないような気もします。
おわりに
並列化を進めると、例えば間にクロスバスイッチなんか入れた場合 Nの二乗で肥大化しますのでなかなか厳しいことになっていく事は容易に想像できます。
ひょっとすると、いずれハードウェアでは難しい事ができなくなり、 MPI みたいなプログラミングモデルの元、シンプルなネットワークで、後はプログラマが頑張るしかない世界に戻るのかもしれませんね。