はじめに
FPGAなどでデータ処理をする場合、その並列性を活かして高性能な処理をするという事はしばし求められることです。
その際にしばし使われるデータ並列とパイプライン並列を整理しておきたいと思います。
データ並列と言うと、AVX-2 のような SIMD(Single Instruction Multiple Data) や GPGPU のような SIMT(Single Instruction Multiple Threads) などでお馴染みかと思います。
一方でパイプライン並列は Verilog など RTL言語で FPGA等を開発する方々と違い、C言語などでプログラミングする方々にはあまりなじみが無い可能性もあるかと思います。
そこで少し具体例を元にこれらを見直してみたいと思います。
少し具体的な例を考えてみる
本当にこんな処理を行う事があるかどうかは一旦置いておいて、画像データに対して
- 処理1 : 逆γ補正を行いリニアな量に戻す (リニアワークフロー)
- 処理2 : 黒レベル補正(オフセット減算)
- 処理3 : ゲインアップ(ゲインを乗算)
- 処理4 : 上限クリップ(1.0以上をクリップ)
- 処理5 : 下限クリップ(0.0以下をクリップ)
- 処理6 : γ補正(ディスプレイの特性に戻す)
というような処理をすべてのピクセルに対して行う事を考えてみて、簡単の為にどの処理も1サイクルで完了するという事にします。
この処理を FPGA で実装すると恐らく下記のような演算器を並べたブロック図の構成になるのではないかと思います。

時間軸で見ると下記のような感じです。

まず、同じ演算を横並びにする「データ並列」について考えます。 入力データは、メモリに格納されていたり、イメージセンサから直接取り出されたりします。またどうように計算結果もメモリに書き込まれたり、あるいは直接ディスプレイに送られたりします。
ここではデータの並列幅について考えることになります。入力元は例えば DDR4-SDRAM であれば 64bit幅で 2400MHz であったりとかで並列に複数ピクセル分のデータが供給されます。またイメージセンサから直接入力する場合も、昨今のものは高速シリアルが並列に何レーンもありますので、こちらもやはり1サイクルに複数のピクセルが並列にやってくるものは増えています。 逆に言うと、この時に データ帯域幅以上のデータ並列を行う意味は FPGA にはありません。 それ以上のデータ並列があっても演算器が遊んでしまうだけです。
次に、「パイプライン並列」について考えます。こちらは 行いたい演算のアルゴリズム で計算の深さが決まります。そしてまた演算の深さ以上の回路リソースは活かされることはありません。
この時点で、データ入出力の帯域とアルゴリズムで、最大能力が決まり、それ以上のFPGAの演算能力は持て余すだけとなります。同じことは CPU や GPU にも言えます。
ですのでデータ帯域当たりにより多くの処理を行おうとすると、より一回のメモリアクセスで深い演算を行えるアルゴリズムを考えるということが重要になります。いわゆる B/F の話であり、多くの科学計算でより性能の出るアルゴリズムの工夫が行われているわけです。
この時、データ並列もパイプライン並列もどちらも明示的に扱える FPGA はいろいろと有利さもあるのではないかと考えていたりもします。
例えば筆者の LUT-Network での画像認識などはFPGAを活用した非常に深いパイプラインの例かと思います。

筆者はしばしこの手の回路をイメージセンサからの入力やディスプレイ出力に直結し、外部メモリを使わないようなことをよくやりますが、メモリほどのデータ帯域の無いイメージセンサであっても多くの演算量を効率的に適用することが出来るケースがあります。
CPU や GPU を考えてみる
CPUやGPUのSIMDやSIMT の特徴は、文法上はデータ並列しか存在せず(CPUの中ではパイプライン処理はされますが)、全てを並列に考えるのが特徴になるかと思います。
試しに CUDA で書いてみたものが下記です(動かしてはいないので間違いはあるかもですが)。
// CUDAで書いてみる __global__ void Kernel1(const float *src, float *dst, int stride) { int x = blockIdx.x * blockDim.x + threadIdx.x; int y = blockIdx.y * blockDim.y + threadIdx.y; float x = src[y * stride + x]; x = pow(x, 2.2f); x = x - 0.2f; x = x * 1.5f; x = min(x, 1.0f); x = max(x, 0.0f); x = pow(x, 1.0f / 2.2f); dst[y * stride + x] = x; }
これは、1ピクセルごとに1スレッドを割り当てるパターンです。CUDAではこれが 32スレッド集まった WARP という単位でまとめて実行される SIMT の構成を取ります。
この場合プログラム上は画像のピクセル数だけの並列記述となるので、データの帯域よりも並列演算器の並列度が大きい という事が起こります。 ではこのとき実行はどうなっているかを想像すると、恐らく下記のようになっていると、思われます。
- 多くのスレッドのうち物理的に割り当て可能な範囲で WARP にスレッドが割り当て実行が開始される
- 各スレッドはデータの読み出しを行いデータ帯域の中で最初に読み込みが終わったWARPが処理を開始する
- 以降、データが読みだされた順に次々と別のWARPが処理を開始する
- 処理の終わったWARPから順にまだ未割当のスレッドを割り当てる
- すべてのスレッドが完了するまで続ける
という、なかなか複雑な事が起こると予想しています。
下記、筆者の想像なので間違っているかもしれませんが、イメージ図です。
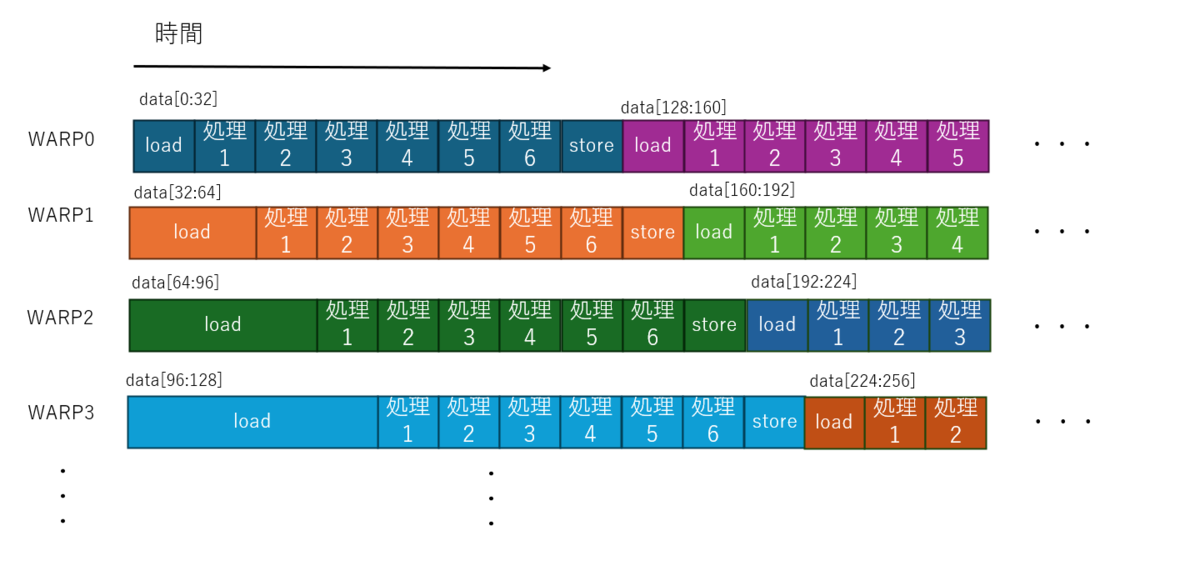
本当に一斉に起動するのか? とか、load と sotre が重なってるところは片方待つのでは? とか、キャッシュの挙動は? とかいろいろ気になる複雑な話はいっぱいあるわけですが、細かいところを無視して想像するとこんな感じではないかと思います。
結果論から言うと、一応はデータ供給幅に応じた単位でパイプライン並列的な動きにはなるのかとは思います。
しかしながらこれらを明示的に行っている FPGA に比べて、複雑度が高いのは間違いないかと思います。また、CPU/GPUは基本的にはロードストアアーキテクチャであり、メモリからメモリへしか計算できないという特徴がありますのでしばしメモリ帯域へのコスト要件も高くなりがちです。
メリットとしては
- データ並列しか意識しなくてもある程度自動的にパイプライン並列にもなる
- 一つのコードを書いておけば、メモリ帯域やコア数の違ういろんなGPUで同じコードが実行できる
と言ったところが予想され、逆にデメリットを列挙すると
- 各コアが持つ何でも出来る演算器が毎サイクル1種の演算しかしない
- 演算が浅く、コア数 > バス帯域 となると多くのコアが load 待ちでストールする
- メモリ帯域やキャッシュなどにコストが転嫁されがち
- 一度メモリに入れないと計算できない
- リアルタイム保証もやりにくい
などではないかと思います。
おわりに
結局のところアルゴリズムとマッピング先のハードウェアが決まっていると、性能限界は自ずと決まってくる気はしています。
そうなってくると、性能限界を目指して実装を頑張るよりもアルゴリズムの方をハードウェアに合わせて改修する方が面白みがありそうな気もしています。
このときにGPGPUなどをターゲットにしたアルゴリズムは多数ある反面、FPGA向けのアルゴリズム改善は人口が少ない分、比較的差別化しやすい気がしています。そういったことを考えるときに二つの軸の並列性を念頭に置いておくことが何かの役に立てば幸いです。