はじめに
前回ぐらいからIIR型のネットワークに向けていろいろやってるのですが、道が長そうなのと、夏季休暇もあって少し進展もあったので途中経過をブログに残しておきます。
LUT-Networkのおさらい
当サイトでは主にFPGAで超リアルタイムなバイナリニューラルネットワークを扱う為の研究っぽいことを(趣味で)行っています。
そのための専用の学習環境としてBinaryBrain の開発なども行っており、要点は下記の2点です。
オーディオの世界で 1bit ADC とか D級アンプとか聞かれたことがある方もおられるかもしれません。オーバーサンプリングが肝ではありますが、1bitまで量子化してなお高品質になるぐらいです。
これらはアナログ値を、非常に高いサンプリングレート(オーバーサンプリング)によって0と1 の発現確率に置き換えることによって実現されているとも言えます。
画像なども元々は、光子が網膜の桿体細胞に当たるか当たらないかのデジタルな事象の頻度を人間が勝手に脳内でアナログ値として認識しているにすぎません。詳しくないですが、そもそも脳のシナプスも発火する/しないのデジタルに近い動きのようです。「1bitに量子化」というと粗っぽくて情報が無くなりそうにも思えますが、扱い方次第では全くそんなことはなく、むしろ効果的に信号処理ができる例も少なくないのではないかと思います。
ということで、オーバーサンプリングとStochasticモデルを用いればバイナリでもアナログ値を効率よく扱える可能性がありますので、特にバイナリ演算が得意なFPGAを使って高効率でリアルタイムなディープラーニングを目指そうというのが、現在の LUT-Network の方向性です。
リアルタイムコンピューティングおさらい
もともと筆者が RealTime-OS 作って遊んでいたらCPUに満足できなくてFPGAに手を出したという経緯もあって、リアルタイムコンピューティングは当サイトの一貫したテーマでもあります。LUT-Network もそもそもこの経緯で生まれたので少し触れておきます。
リアルタイム処理の定義はいろいろあるのですが、今私が考えているのは「リアルタイムに適した計算機アーキテクチャとは何か?」というお話になります。なかなか難しい問題なのですが、現状は 「今持っている最新の情報を最善の方法で、且つ、即時性に保証をもって出力に反映できる計算機」 というように考えています。
この考え方の上で考えるに
- 入力と出力は最短経路で演算を施して出力されるべき
- メモリは過去の情報にアクセスする為だけに使うべき(情報を過去から未来に送るデバイスと捉える)
- アルゴリズムも同様に「今持っている最新の情報を最善の方法で出力にできるだけ即時に反映できる」を目標に検討されるべき
- アルゴリズムは物理空間の制約や外部デバイスの特性を考えて検討されるべき
- これらを目指しつつ現実的なリソースにマッピング可能な最適解を探る
というような事が考えられます。
現状のノイマン型のCPUやGPUなどのアクセラレータの欠点の一つは、そのアーキテクチャがメモリ間演算(ロード/ストアアーキテクチャ)を前提に組まれている点にあると考えています。 良くも悪くもメモリと言うデバイスは、何の演算をすることもなく保持している情報を情報を未来に送ってしまいますので、これを前提にアーキテクチャを組むと、不特定な遅延要因になりがちなわけです。これも一種のノイマンボトルネックと言えるかもしれません。
そこで当サイトでは、基本的に演算器主体でアーキテクチャを考えており、如何にメモリを最低限に入力と出力を直結するかを考えてきました。 過去になんども出した絵なきはしますが、下記のような感じです。
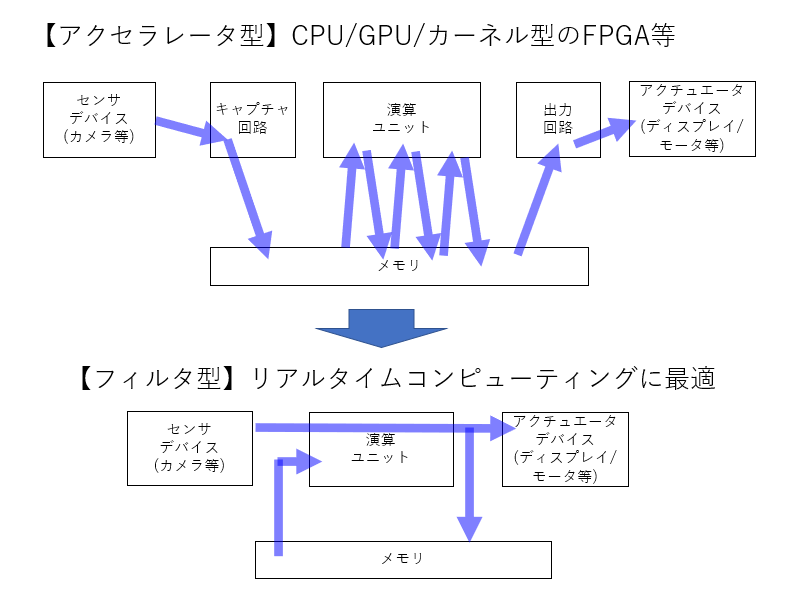
何という事はない、普通の IIR(Infinite impulse response) フィルタの基本形に他ならないわけですが、この枠組みでいろんな計算機作ることを目指しているわけです。
構成はシンプルですが、FPGAでプログラミングする以上演算ユニットは自由にプログラミングでき、メモリには何でも保存できるし何でも読み出せる点でチューリング完全を保っており、且つ、入力と出力を最短パスで繋ぐ術が残っているわけです。そしてなにより昨今のFPGAは安価かつ大規模になってきていますのでかなり複雑な処理も可能になってきています。
プログラミングモデルとしては状態空間モデルになるでしょうか。固定時間処理を保証しやすいのもFPGAの良いところですので、いろんなリアルタイムアプリケーションがこの枠組みで作成可能と思います。
なお、ここまでですと、特にリアルタイムコンピューティングと意識せずとも従来から世の中にいっぱい存在するアーキテクチャとは思うのですが、「この枠組みにこだわりながらディープラーニングやってみよう」というのが、LUT-Network の狙うところであり、普通のディープラーニングと似て非なるものになってる所以です。
IIR型セマンティックセグメンテーション
では、ようやく本題です。
本サイトではすでにLUT-Netを使ったセマンティックセグメンテーションは実施済みなわけですが、この時はメモリは一切使っておらず、1フレーム内で 3x3 の畳み込み層を大量に並べることで何とか手書き文字(MNIST)の28x28ドットのサイズをカバーしていました。
力業であって、リアルタイム性に関してはそれらにのインパクトはありましたが、非常に非効率ですし広い空間が認識できません。
そこで今回ちゃんと IIR をやろうという事で、現在下記のようなブロック図を検討中です。
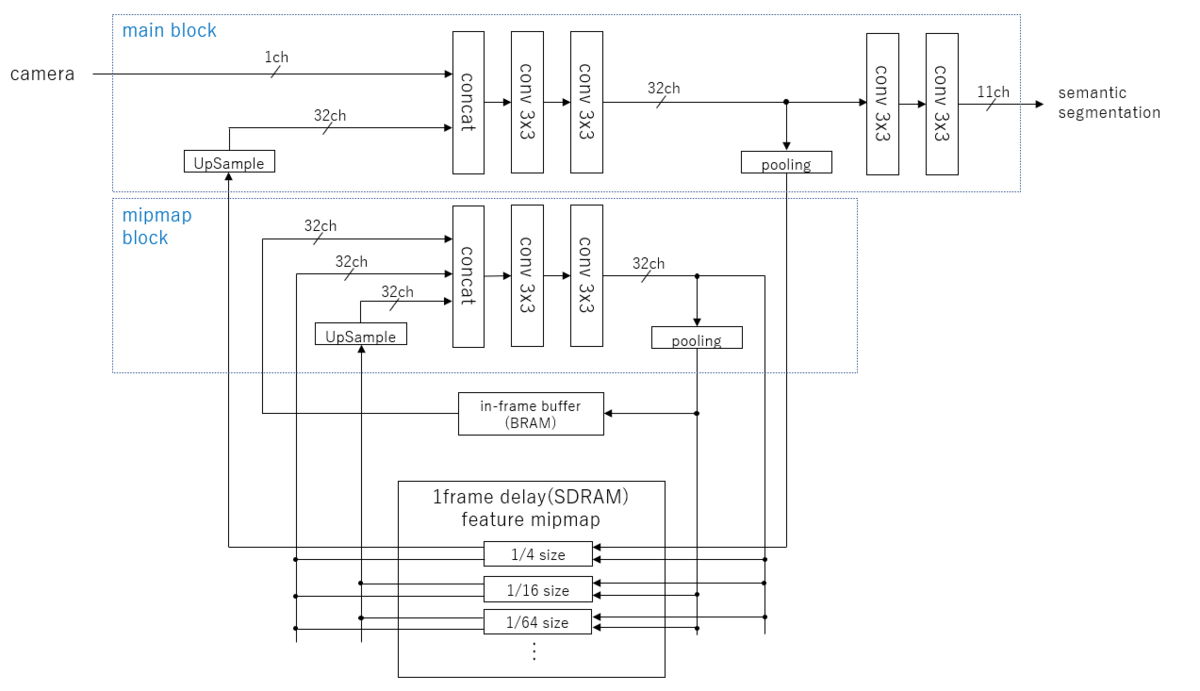
前に述べたようにFuture map の保存にミップマップを使うことで、1/3フレーム分の処理帯域とデータ帯域で無限段階のスケーリングに対応可能なIIRフィルタが作れるのではないかと言う案です。 1/1スケール用に1個演算器がフル稼働しますが、もう一個ユニットを設ければサイズは無限に対応可能です。
時系列で書くとこんな感じにしたいという目論みです。
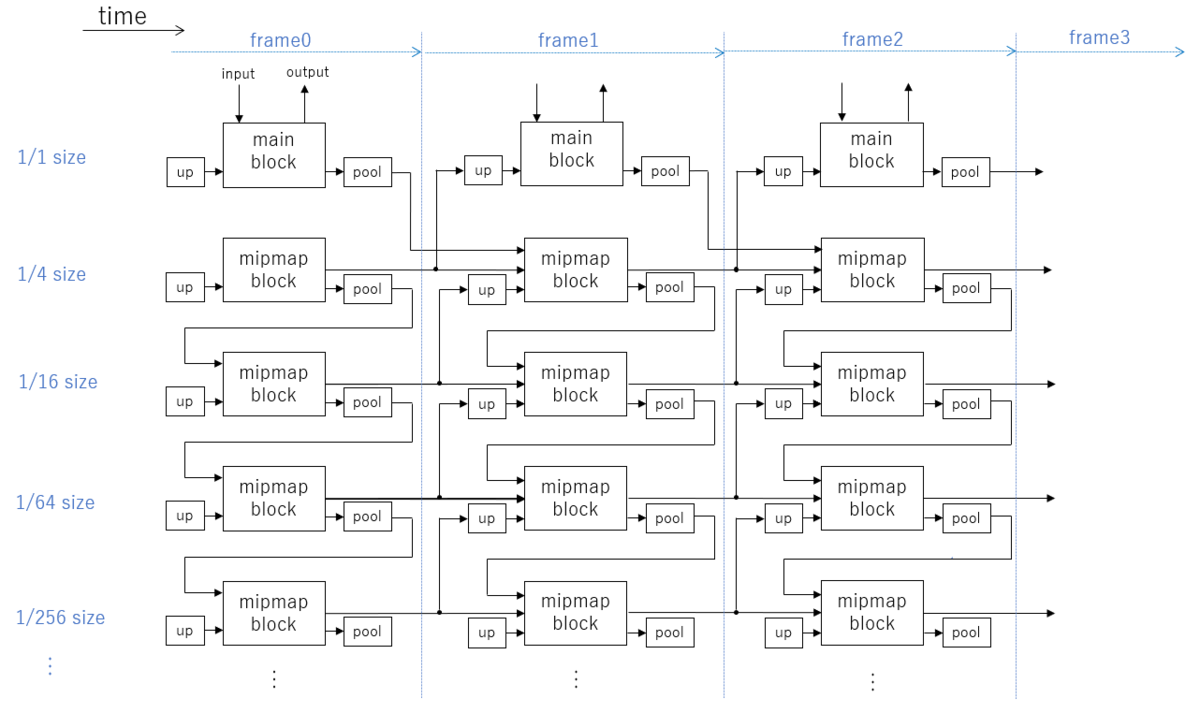
1000fps のオーバーサンプリングされた世界で使えば これで U-Net++ のような計算ができるのではないかと考えている次第です。
で、 BinaryBrain の改修に取り組み中なわけですが、もともとが LUT-Network のコンセプトの原理検証用だったコードからの進化なので、RNN要素も入ってくるこのような複雑なネットが学習できるか、当初からかなり不安でした。
が、規模が大きくないこともあり PyTorch で FP32 でバイナリ(+1/-1 を格納するのに32bit使う贅沢仕様)を試したところ案外行けそうだったので、LUT-Network で挑戦するために、BinaryBranin の改修頑張ってみました。
結果、PyTorch と同じネットを学習できるところまで来ました。
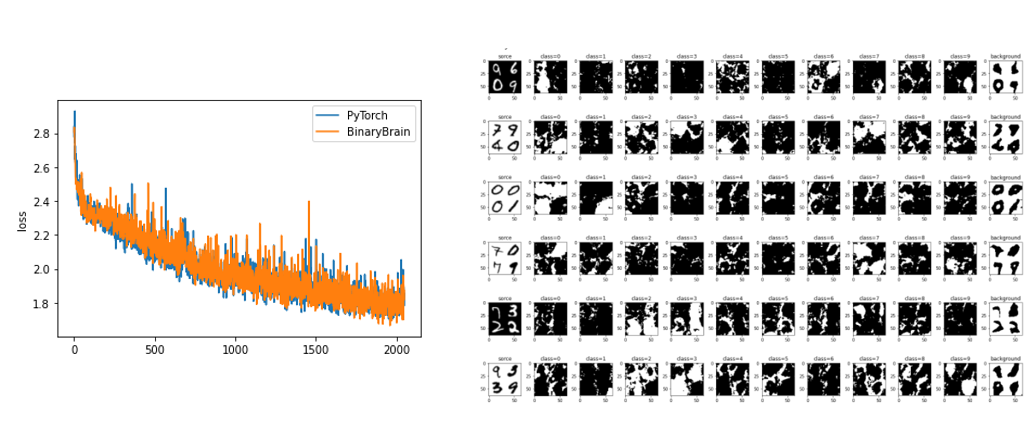
バイナリ化していますのでいろいろイマイチですが、オーバーサンプリングした上でStochastic性を活かして後処理を入れればもう少し改善しそうには思います。 10クラス分類にそのまま「背景」を加えて11クラス分類にしていますがなかなか重み付けが難しいですね(背景と数値区別は別々に認識した方が良いのかもしれません)。
まだ各層の出力に Binarize を入れているだけで、DenseAffine であって LUT-Net になっているわけではありませんが、PyTorch でやっていた実験を BinaryBrain に持ち込めたので、次のステップに進むことが出来そうです。
おわりに
なお、今回の内容はまだ develop ブランチにしかありません。いろいろ改修点が多いので、従来サンプルが動かなくなってないかとか心配事多数なので、リリースにはもう少しかかるかと思います。
途中経過以外のなにものでもないブログ更新でしたが、引き続きのんびり取り組んでまいりたいと思います。