はじめに
先ほど BinaryBrain 4.2.4 をリリースしましたので少しだけ時事ネタ的にプログを書こうと思います。
github.com
もともと FPGA の基本構成要素である LUT を LUT 構成のまま誤差逆伝搬で学習させてしまおうというのが、以前発表したLUT-Net の趣旨ですので、そこから C言語 を出力するのは逆コンパイル してまたコンパイル するような話にはなってしまうのですが、今回少しトライしてみましたので使い方などを少しご紹介できればと思います。
HLSチャレンジがきっかけ
第10回ACRiウェビナー を視聴させて頂いていたところ、HLSチャレンジ に新しい問題が追加されるとの事を知りました。
さっそく見てみるとHLSでCNNに取り組むのに大変よい良問が設定されていて、私も頭をひねっている途中なのですが、なんとこの中にフリー部門が1問追加されていて「MNIST を 90% 以上の認識率で達成できれば何をやっていい」という、なかなか野心的でわくわくするものが設定されておりました。
当然いろんなやり方があると予想されますが BinaryBrain の HLS 対応を考えるのに十分なモチベーションになりそうでしたので、ここぞとばかりにやってみました(他の方が本気になるとすぐ抜かれそうではありますので(笑))。
結果から言うとまだ誰も提出していない部門に一番乗りしたがゆえに一時的に一位です(当たり前ですが)。
ただし、文字列制限などもあり、BinaryBrain の出力をかなり変則対応しての提出となってしまいました。ですので、最終的にリリース版の BinaryBrain に実装した機能では HLSチャレンジにはそのまま提出できないのですが、良くも悪くも「BinaryBrain で HLS が使えるか試してみるきっかけになった」 ということでご容赦ください。ひとまず簡単ながら HLS 出力機能が付きました。
当初なかなかHLSに LUT を推論してもらえずに困っていたのですが、試行錯誤の末どう書けば意図通り解釈してもらえるか見えてきたのはHLSの良い勉強になりました。
BinaryBrain の HLS 用コード出力機能を使ってみる
セットアップ
こんかいは Windows11 (22H2) の WSL2 で Ubuntu 20.04.4 LTS を 使います。NVIDIA の GPU ボード と CUDA Toolkit 11.6 が準備されている前提とします。
ちなにみ私の使っているのは NVIDIA GeForce GTX 1660 SUPER です。
以下は私の環境なので、随時ご自身の環境に読み替えてください。
画像データの準備に Torchvision を使いますので PyTorch も入れております。
# とりあえず仮想環境作る
pyenv local 3.9.12
python -m venv .venv
source .venv/bin/activate
# 必要なものを入れる
pip install numpy
pip install tqdm
pip install pybind11
pip install ipykernel
pip install jupyterlab
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu116
pip install binarybrain==4.2.4
# リポジトリゲット
git clone -b ver4.2.4 --recursive https://github.com/ryuz/BinaryBrain.git
# Jupyter Lab に仮想環境を追加して起動
python -m ipykernel install --user --name=bb4.2.4 --display-name=bb4.2.4
jupyter lab
# 以降ブラウザにて BinaryBrain/samples/python/mnist/MnistDifferentiableLutHls.ipynb を開く
学習実施
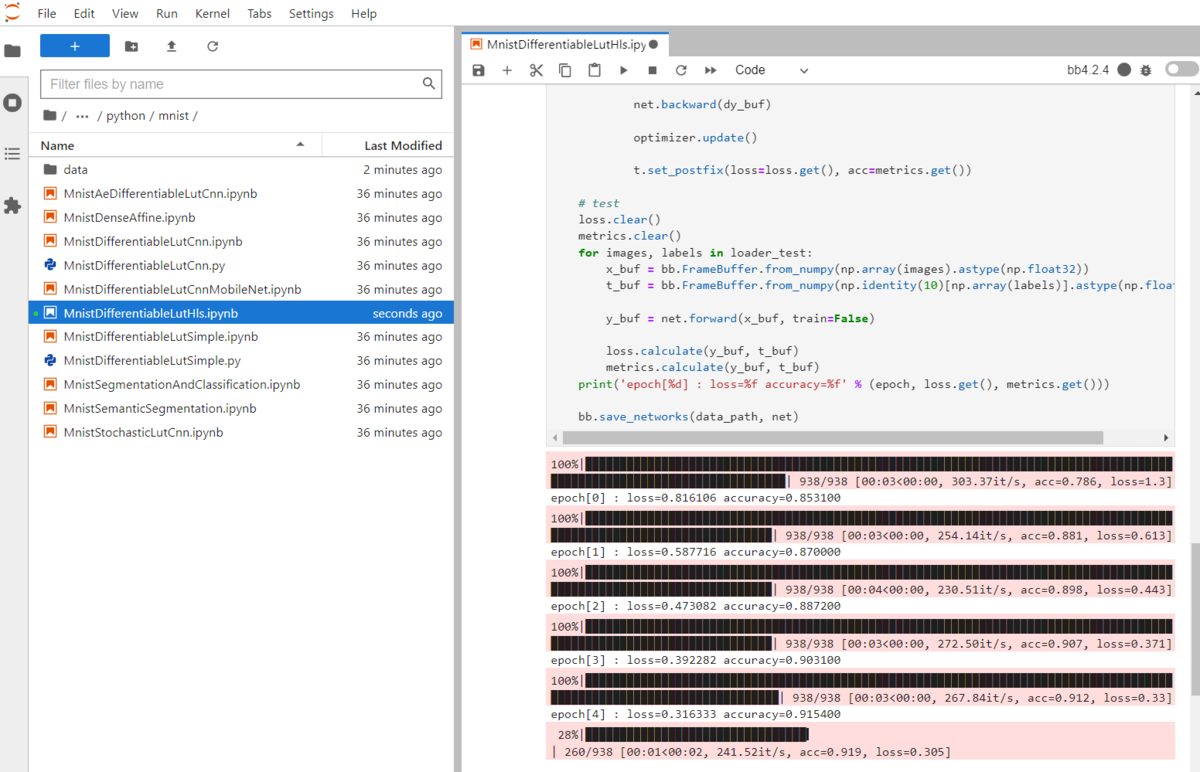
BinaryBrain/samples/python /mnist/MnistDifferentiableLutHls.ipynb を開いた後に、環境を先ほど作った bb4.2.4 に切り替えて実行すれば、学習が始まります。
下記のように進んでいきます。
学習風景
最後まで流れると
BinaryBrain/samples/hls/mnist/simple/src/MnistDifferentiableLutHls.h
BinaryBrain/samples/hls/mnist/simple/testbench/mnist_test_data.h
の 2つのファイルが生成されます。
詳細は MnistDifferentiableLutHls.ipynb の中を見ていただければと思いますが、今回は CNN ではなく単純な多層パーセプトロン もどきの構成にしており、HLSチャレンジのフリー課題にかなり近いサンプルの構成になっております。
全部 LUT層だと HLS の意味が薄いので、最後に INT8 での Depthwise Dense Affine 層を1層だけ入れております。
----------------------------------------------------------------------
[Sequential]
input shape : [1, 28, 28] output shape : [10]
--------------------------------------------------------------------
[Binarize]
input shape : {1, 28, 28} output shape : {1, 28, 28}
--------------------------------------------------------------------
[DifferentiableLut6]
input shape : {1, 28, 28} output shape : {256}
binary : 1 batch_norm : 1
--------------------------------------------------------------------
[DifferentiableLut6]
input shape : {256} output shape : {128}
binary : 1 batch_norm : 1
--------------------------------------------------------------------
[DifferentiableLut6]
input shape : {128} output shape : {10, 64}
binary : 1 batch_norm : 1
--------------------------------------------------------------------
[DepthwiseDenseAffineQuantize]
input shape : {10, 64} output shape : {10}
input(64, 10) output(1, 10)
----------------------------------------------------------------------
HLS を試す
HLS のサンプルディレクト リに移動して、Vitis HLS をセットアップします。
cd BinaryBrain/samples/hls/mnist/simple/
source /tools/Xilinx/Vitis/2021.2/settings64.sh
src/mnist_sample.cpp がメインのコードで、testbench/tb_mnist.cpp がテストベンチになっています。
先ほど学習で作ったソースコード を include してコンパイル するようになっています。
csim を試す
ここで
make csim
と打ち込むと C言語 シミュレーションが走ります。
今回は下記のようになりました。90%程度合えばOKなのですが今回運よく全問正解しています。
out[0]=7 exp:7 ok
out[1]=2 exp:2 ok
out[2]=1 exp:1 ok
out[3]=0 exp:0 ok
out[4]=4 exp:4 ok
out[5]=1 exp:1 ok
out[6]=4 exp:4 ok
out[7]=9 exp:9 ok
out[8]=5 exp:5 ok
out[9]=9 exp:9 ok
out[10]=0 exp:0 ok
out[11]=6 exp:6 ok
out[12]=9 exp:9 ok
out[13]=0 exp:0 ok
out[14]=1 exp:1 ok
out[15]=5 exp:5 ok
out[16]=9 exp:9 ok
out[17]=7 exp:7 ok
out[18]=3 exp:3 ok
out[19]=4 exp:4 ok
accuracy = 20/20
合成してみる
単に
make
と打つと論理合成が走ります。結構時間がかかりますが
solution_1/impl /export.zip
に、Vivado に取り込み可能な IP が出来上がりました。
合成のレポートを見ると下記のような感じでした。
合成レポート
HLSで書いた乗算を行う DenseAffine はやや大きいですが、LUT層は十分小さくできています。
コシミュレーションしてみる
最後に
make cosim
とすると、コシミュレーションが走ります。
デフォルトで 波形表示に GUI を起動するオプションにしていますので、シミュレーションが終わると Vivado が起動し、以下のように動作が確認できます。
コシミュレーションの波形確認
おわりに
如何だったでしょうか? そういえば BinaryBrain を作ってから、このような一連の使い方をブログに書くのは初めてのような気がします。
チュートリアル であればマニュアルの方に書くのが筋ですから、今回、HLSチャレンジという時事ネタで、少しマニュアルとは違う記事にできてよかったと思います。
おまけ
全問正解もびっくりだったのであとからもう少し学習を進めてみました。今度は20個中2個間違えて概ね 90% という理屈通りの結果となりました。
4と9 や 8と3 の間違いという、なんとなく似た文字として間違えており、深層学習っぽさが少し出たかなと思います。
out[0]=7 exp:7 ok
out[1]=2 exp:2 ok
out[2]=1 exp:1 ok
out[3]=0 exp:0 ok
out[4]=4 exp:4 ok
out[5]=1 exp:1 ok
out[6]=4 exp:4 ok
out[7]=4 exp:9 miss
out[8]=5 exp:5 ok
out[9]=9 exp:9 ok
out[10]=0 exp:0 ok
out[11]=6 exp:6 ok
out[12]=9 exp:9 ok
out[13]=0 exp:0 ok
out[14]=1 exp:1 ok
out[15]=5 exp:5 ok
out[16]=9 exp:9 ok
out[17]=7 exp:7 ok
out[18]=8 exp:3 miss
out[19]=4 exp:4 ok
accuracy = 18/20
件のHLSチャレンジのMNISTフリー部門 ですが、どうやら一番乗りだったらしく 2022/11/21 現在、暫定1位となっています(ほかに誰もいないので当たり前ですが)。きっとすぐに抜かれる気がするので、記念スナップショットです。
HLSチャレンジ暫定一位?
恐らくある程度ランダムに設定されていると思われる本番時の画像入力ですが、90% クリアすればパスできるようですので、決定木の類とかで攻めていけばかなり好スコアが出るのではなかろうかと予想しつつ、ガチ勢の方々の参加を恐々と見守っております。一応 DeepLearning っぽいもので攻めた記念ということで(あわよくばこのまま逃げ切れないかなとも期待しつつ)。