おしらせ
以前Qrunchで書いていた記事の復刻です。
CIFAR-10 の CNN でのバイナリ化検討
CIFAR-10 の CNNを利用して、入力のバイナリ化による影響を評価し、完全なバイナリネット(Fully Binary Network) の可能性を探っております。
以前、Qiitaの方にも記事を書いたことがあるのですが、その続編となります。
はじめに
一般的にネットワークのバイナリ化といっても、初段の層は多値で入力することが多いようです。 一方で当サイトが進めるLUT-Netなどは時間方向へのバイナリ変調など含めて当初からすべてフルバイナリで検証を行ってきた経緯があり、その際にいろいろな試みを行ってきました。
また、ここにきて時間方向への変調だけでなく、チャネル方向(Depth方向)への変調含めて効果が出てきたのですが、従来の「初段の層は多値で入力する」やり方とのベンチマークができていませんので、少し時間を取って定量的な実験を試みた次第です。。 パラメータを変えたいくつかの実験を行ったのでそのログをベンチマークできるようにグラフ化してみました。
「初段の層は多値で入力する」場合、初段の層の出力が32チャンネルのConv3x3だとして、スループット1を目指すと 3x3x3x32=864個の乗算器が必要となります。これはFPGAなどのロジックで回路化する場合に大きなインパクトです。 多くのバイナリネットワークは2層目以降では1bit演算(つまり1ゲート)で1接続を賄うため、非常に回路をコンパクトにできますので、これを初段からすべてバイナリでネットワークを構成できればFPGAなどのハードウェアにDNNを適用する場合に有利になる可能性があり、この点について参考データとできればと考えます。
本記事では、単純に2値化したのでは失われる情報を、時間方向(frame方向)やチャネル方向(depth方向)へ情報を分散させて二値化(時間的に言うと変調、空間的に言うとディザと言うのがしっくりくる語かもしれません)することで、精度の回復がどこまで期待できるかを実験しています。
ネットワークのバイナリ化影響
まず、議論をバイナリネットの入力方法にフォーカスして論じるために、入力のみFP32(単精度実数)で行い、後段をバイナリネット置き換えた従来型のバイナリネットワークをベンチマーク基準に置くことにします。 この段階で、バイナリ化での精度劣化が発生しますので、それをはじめに明らかにしておきます。
ネットワーク構造は
| layer | input size | output size |
|---|---|---|
| Conv3x3 | 32x32x3 | 30x30x32 |
| Conv3x3 | 30x30x32 | 28x28x64 |
| MaxPooling | 28x28x64 | 14x14x64 |
| Conv3x3 | 14x14x64 | 12x12x64 |
| Conv3x3 | 12x12x64 | 10x10x128 |
| MaxPooling | 10x10x128 | 5x5x128 |
| Conv3x3 | 5x5x128 | 3x3x128 |
| Conv3x3 | 3x3x128 | 1x1x256 |
| Conv1x1 | 1x1x256 | 1x1x512 |
| Conv1x1 | 1x1x512 | 1x1x10 |
という、Dropoutなどはないオーソドックスな形状として、各Conv層の中に BatchNormalization層 と、Binarize層 を持たせています。 ここですべての層の出力は Binarize されるので、FP32で入力されるのは初段の層のみとなります。 また、ベンチマークの為の FP32 版は Binarize 層 を ReLU層に置き換えてベンチマークしています。
以下がその結果となります。
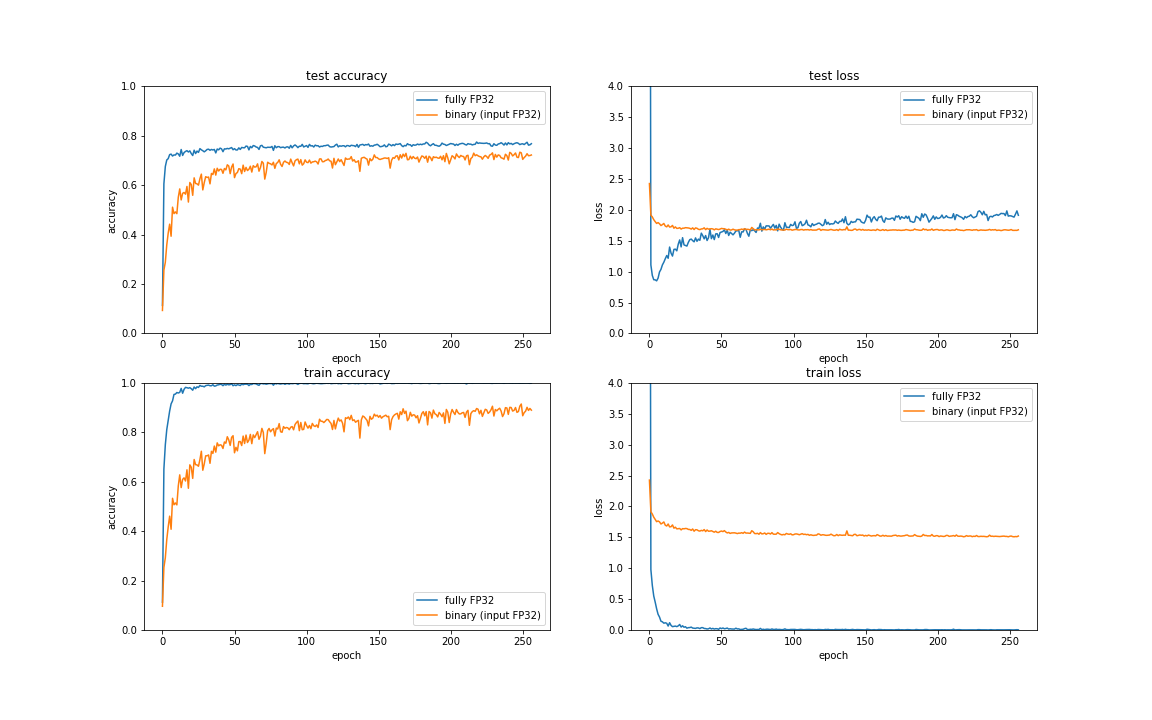
バイナリ化によってtrainデータのaccuracyは低くなっていますが、testデータに関しては過学習の兆候も少なくaccuracy も用途によっては悲観するほどの低下ではないと言えると思います。
今回はネットワークのバイナリ化が趣旨ではなく、入力データのバイナリ化のベンチマークが趣旨であるため、この入力のみFP32としたネットワークをベンチマーク基準として実験を行います。
時間方向のバイナリ変調
ここから Fully Binary ネットワークの実験として、入力から完全にバイナリ化して実験していきます。
その際、まず前回Qiitaに書いた記事 と同じ方法を条件を揃えて再計算しておきます。バイナリ化の閾値を変調する方法です。
この方法では同じ画像フレームに対して異なる閾値で作った二値化画像フレームを同じネットワークに通して結果を平均化することで精度向上を図ります。この方法の利点はバイナリネットワーク自体は1種類であり、回路規模が小さいことと、出力も多値で得られることである。 デメリットは何度もforward演算を行う必要があることで、計算時間が多くなることです。
これは原理的に音声信号など1次元データで用いられる 1bit ADC のバイナリ変調に近いものと考えており、高速度カメラなどを用いてオーバーサンプリングを行うことで、階調方向の分解能を時間方向に拡散させる(そういう意味ではディザの一種)事も可能と考えておりますので、よりリアルタイム性の高いアプリケーションで効果を発揮する可能性があると考えます。
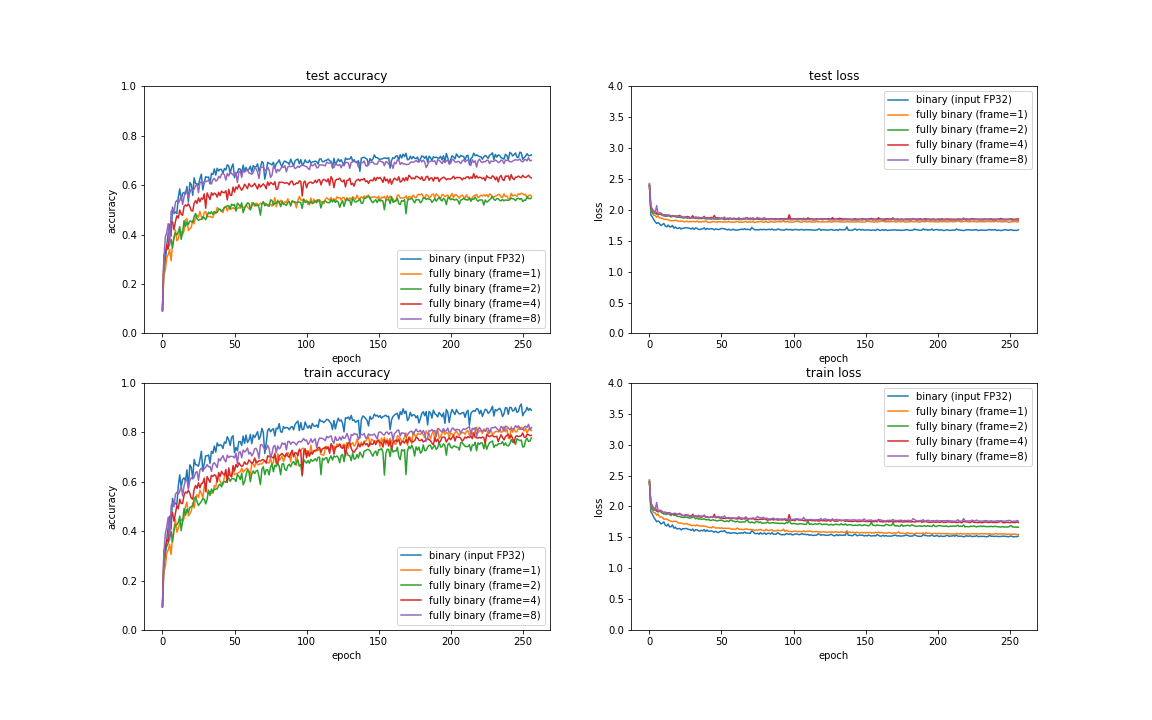
フレーム数を増やしていくと精度が向上していくことがわかり、FP32に迫る勢いです。閾値の違うものを同じ回路に入れて再集計するだけで精度が上がるという点は非常に興味深いと考えます。 今回、時間とGPUのメモリの関係で 16倍までしか実施できていませんが、さらに増やせばさらなる精度向上も期待できます。
チャネル方向(depth方向)への変調
ここからが新しい取り組みです。 従来の画像認識におけるバイナリDNNの入力はRGB 3チャネルのFP32を特定の閾値で2値化して、3チャネルのバイナリ入力としていました。 ここで、異なる閾値で二値化することによってdepth方向に情報を拡散させる実験を行っいました。 例えば、depth=4 では、閾値を4段階用意して、12チャネルのバイナリ入力としています。これは MSB 2bit 分の情報を入力することになりますが、6入力LUTなどを備えるFPGAなどでは、素子1個で6bitまでの2値化は行えるため、殆どリソース消費せずにこの入力を作ることができると考えられます。 また2層目以降は32チャンネルや64チャネルの層を構成するため1層目がその水準に増えたからと言って全体のインパクトは大きくは変わらないと考えます。 したがってこの方法がうまくいくと、少ないリソース増加で高い性能が出せるバイナリネットワークが構成できる可能が見えてきます。
以下がその結果です。
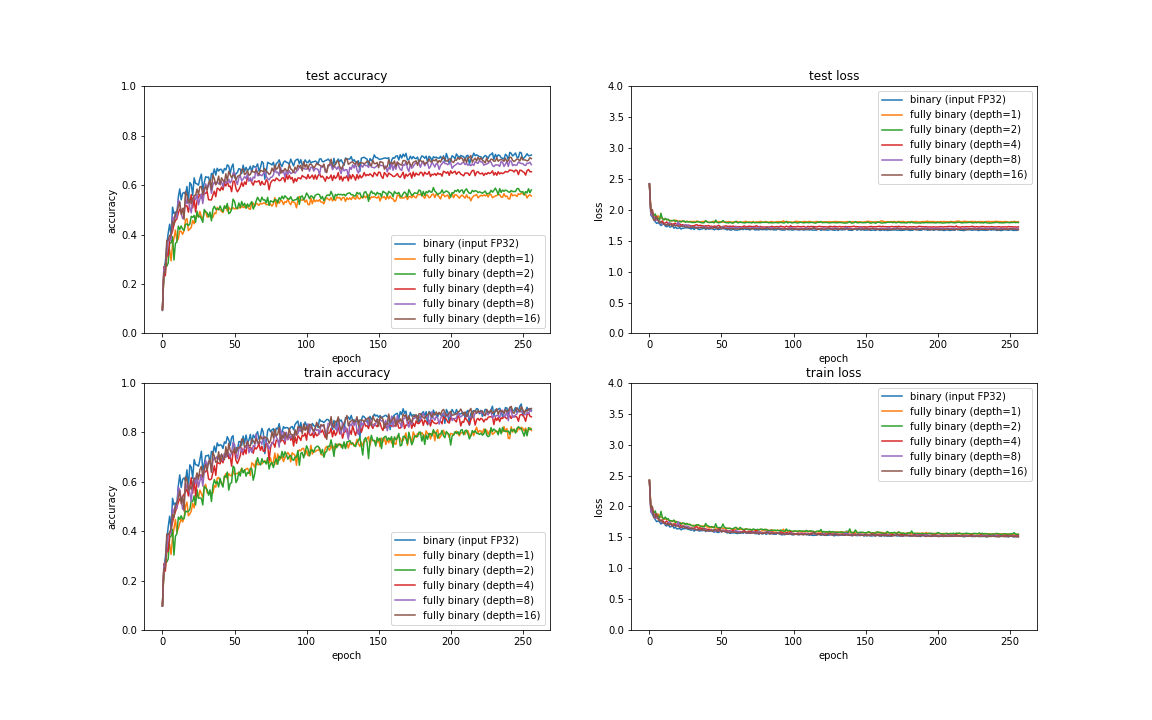
Depth数を増やしていくと精度が向上していくことがわかります。こちらもほぼFP32に迫る勢いです。 FP32が8bitフルに使っているのに対して、現在まだdepth=16の4bitまでしか試せておらず、今後さらなる向上が狙える可能性もあります。
frame変調とdepth変調のハイブリッド
さて、さらに発展形として、ここで述べたframe変調とdepth変調は共存可能です。 具体的には depth 変調の閾値を、さらに frame変調で変化させることができます。
いくつかの組み合わせパターンで実施してみたものが下記です。
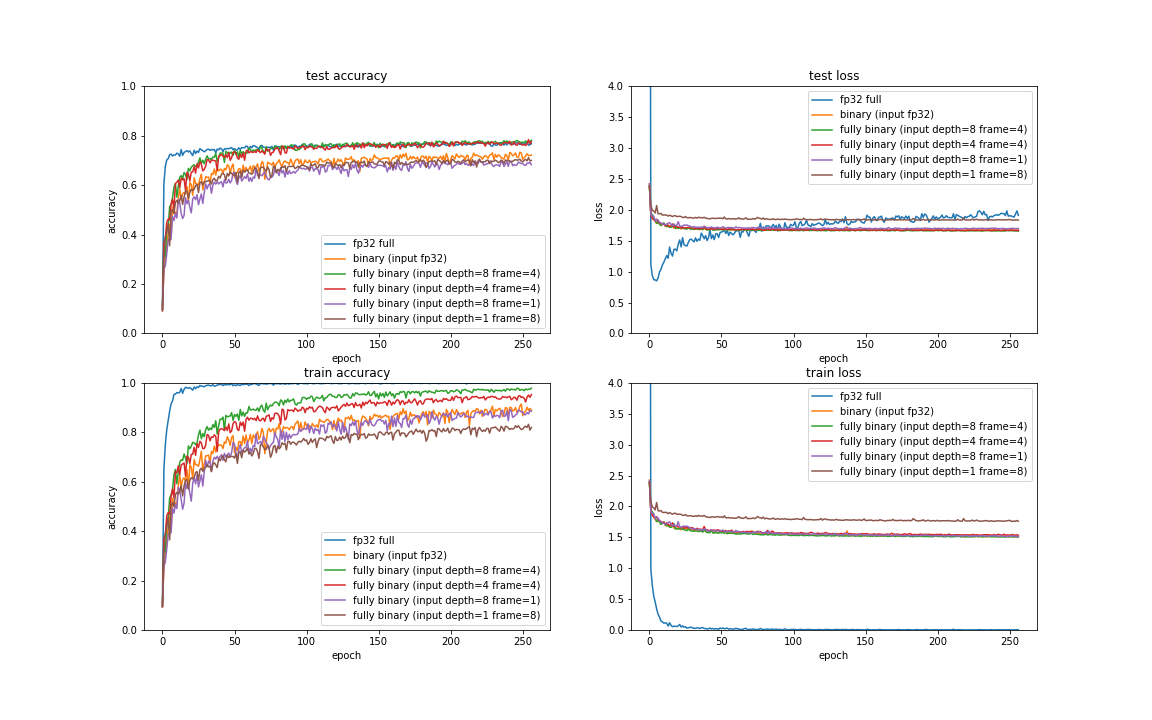
驚くことにFP32入力を上回っただけでなく、testデータで全層FP32のフルCNNと同等の結果がでてしまいました。 frame方向の変調が、frame方向に畳み込みやってると考えれば同じパラメータの回路とはいえ途中の層のチャネル数が増えているとも解釈可能なので、バイナリ部分の総演算量がFP32を上回っており、その点で勝っている可能性が考えられます。
そしてこれももっと倍率をあげる事が可能であるため、今後さらに性能向上できる可能性があります。
参考
以降、おまけですがいくつか補助情報を記載します。
ネットワーク構造
今回のDepth変調のネットワークを図示したものです。
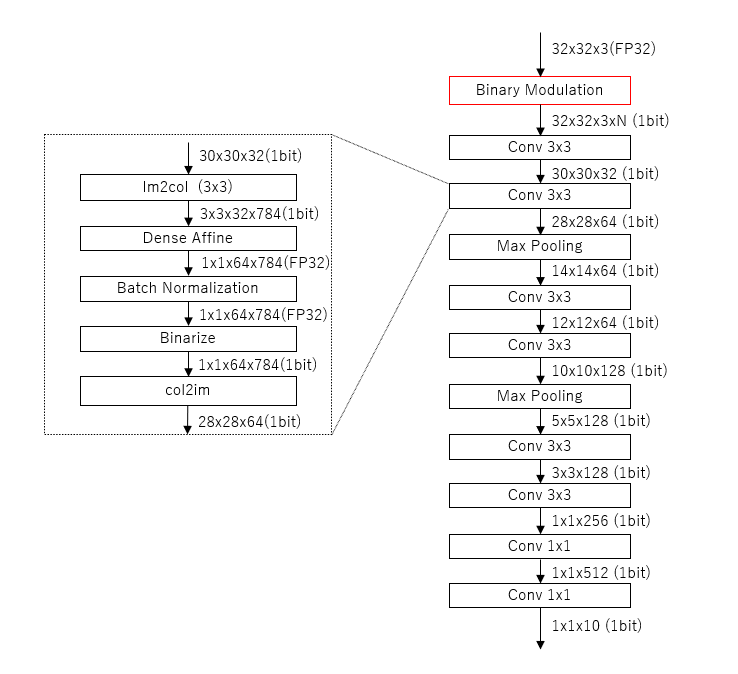
赤枠のBinary化部分をいろいろとパラメータを変えて実験した次第です。
バイナリ化の可能性について
現在当方で進めている LUt-Netにおいて、バイナリ入力をバイナリ出力する層の効率的なFPGA回路化の可能性がかなり見えております。 少なくともCNNの前段4層程度まではLUT-Netに置き換えても同程度の性能が出せることが見えはじめており、Fully Binary Network の可能性を評価しておくことは非常に重要です。
また、LUt-Net以外にも1bit量子化を行う XNOR-Net や、 2bitの量子化を行う BlueOil など、様々な量子化を推し進めたFPGAソリューションは増えてきておりますので、入力のバイナリ化部分だけでも様々な応用があると考えます。
ソースコード
まだ安定板になっていませんがこちらです。 https://github.com/ryuz/BinaryBrain/blob/ver3_develop/tests/cifar10/Cifar10BinarizeTest.cpp
bit数削減影響
そもそもの入力データの量子化影響の程度を見ておきたく、 FP32 で演算する普通のCNN にて、8bitの画像データ入力(3色256階調)をMSB 側の数bitだけ残るようにマスクした場合の量子化影響を実験しております。
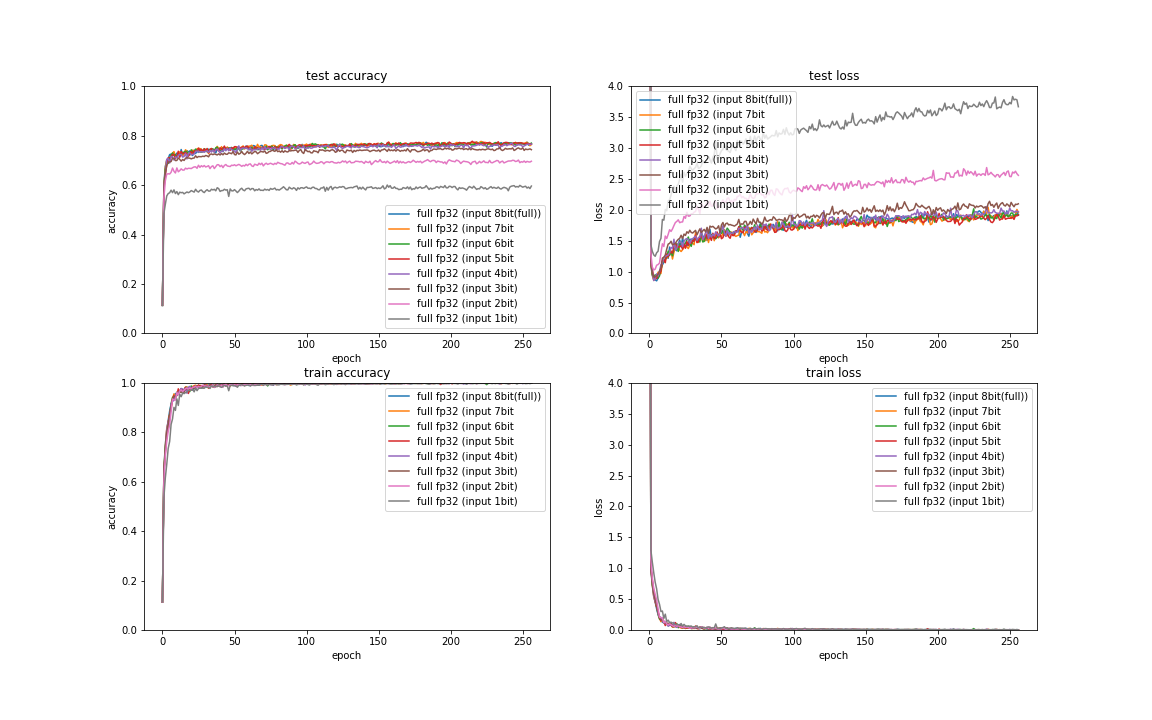
グラフを見る限り、例えば上位4bit(3色16階調)あれば劣化は十分少ないと考えられるようにも思います。 CIFAR-10ではあまり下位bitの細かい部分までは認識に必要ないのかもしれません。