はじめに
少し前にUltra96V2 で FPGA化した リアルタイムOS を試すサンプルと言うものを公開しました。
作りっぱなしになっていたので、まだ碌にテストも出来ていない状態ですが、原理実験的には成り立っていそうですので、少し解説記事的なものを書いておこうと思います。
SystemVerilog + Rust という組み合わせは、現状私にとってリアルタイムシステムのプログラミングに欠かせないものになりつつありますが、その一つの形としてご紹介できればと思います。
ちなみにハードウェアとの相性の良さから、もろもろID番号での指定としており、かなりμITRON風味な仕上がりになっています(今のところは)。
FPGA化RTOSの概要
今回試みたROTSのFPGA化は、RTOSで使われるタスク/セマフォ/イベントフラグなどをZynqMPのPL(Programmable Logic)上にロジック回路として実装することでRPU(Cortex-R5)にRTOS機能を付与しようというものです。
PLのロジック上で現在実行すべきタスクの算出を完了させることで、Cortex-R5 側にはタスクスイッチの機能だけ実装すれば済むようにしようというものです。Cortex-R5 はTCMを有しているのでこのサイズに収まる範囲のコードではかなり高いレベルでリアルタイム保証ができるのですが、ここからさらにRTOSの一部機能をPLにオフロードすることでTCMの節約とともにリアルタイム性向上を狙っています。
タスク数やセマフォ数などの上限はPL用のロジック合成時に指定するので、余裕をもって確保しておくか、都度ロジックの再合成をするかなどが必要ですが、PLも含めてソフトウェアと考えればFPGAらしいアプローチと言えるのではないかと思います。今回は16個とかそのぐらいのオーダーの個数のタスク数を想定して試作しております。
また、PL上にRTOS機能を持っている関係上、イベントフラグのセットなどを、他のロジックから直接的にシグナルすることができ、基本的にはRPU側で従来のような割り込みハンドラの記述はほとんど不要になると考えています。多くの割り込みコントローラが割り込み優先度の管理機能を持っていますが、PLロジックから直接的にタスクが起動できれば、タスク優先度のみに統一して同じことがシンプルに実現できるためです。
今回実装したRTOSを順に解説していこうと思います。
RTOSコアの操作
CPUからは、メモリマップドI/O として特定のアドレスを読み書きすることで操作することを前提としています。筆者の好みからWISHBONEバスで受けていますが、ラッパーをいれて AXI4-Lite でのアクセスも可能です。
特定のアドレスへ書き込みを行うことで、「指定タスクを起床」、「指定したセマフォを返却」、などのあらゆるOSのAPI的な状態変化のトリガーとしています。
また、PLの RTOS コアからCPUへは、irq 信号を使って RPU へ通知を行っています。CPU側がやるべき処理は 「irq を受けたら、RTOSコアから実行すべきタスクIDを読み出してタスクスイッチを行う」ことになります。
個人的には RTL記述派なのでGUIはあまり使っていませんが、少し試したところ BlockDesigner を使って下記のように繋ぐことも可能なようです。
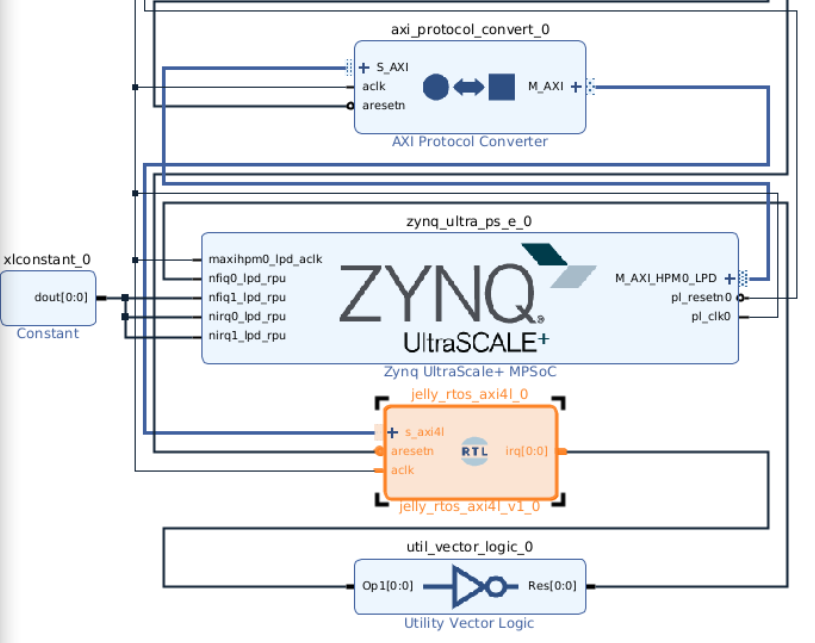
タスクキューの実装
RTOSで利用されるキューは主に、優先度キュー/FIFOキュー/タイムアウトキューなどありますが、今回タイムアウト機能はタスク付属機能として実装してしまったので、主にFIFOキューの上位互換となる優先度キューの話となります。
CPUのみで実装されるキューの場合、各操作の最悪実行時間はタスク数Nなどで制約され O(Log N) などになるケースがありますが、FPGA実装した場合は固定時間 O(1) となる実装が可能です。
例えばタスク数の上限を16個として合成する場合、例えば優先度が 0~15 の 16段階あったとして、4bit の比較器を 16個生成するようなことは Zynq のような規模のPLにとって大きなコストではありません。そして、タスク数だけ比較器が生成できると、優先度キューへのタスク追加が極めて容易に行えます。
キューが最大タスク数の16個格納できる容量があるとして、各段で
- 今保持しているタスク優先度が、追加するタスクの優先度以上ならそのままにする
- 今保持しているタスク優先度が、追加するタスクの優先度未満なら保持内容を後ろに送る
- 2に該当してさらに前が1であれば、保持内容を後ろに送った後、新タスクを取り込む
という、たったこれだけの単純ルールが16並列で動くだけでソートされた場所への挿入が1サイクルで完了します。
削除したりするときも、取り出しヶ所の後ろを一斉に前に送る操作をするだけです。 優先度の比較、タスクIDの比較、前に送る、後ろに送る、などの基本機能を持ったユニットを数珠繋ぎにするだけで好きな数のキューが出来上がります。
FIFOキューも、優先度キューから優先度比較を取り除く(すべて同一優先度とみなす)だけですので同様に実装出来ます。
タスク機能
比較的メインの機能が集まっているのがタスクオブジェクトとなります。
やり取りする相手が多いので多少長いコードにはなっているのであるが、やっていることはタスクの状態管理だけです。
タスク生成時にはスリープしており、起床されると優先度キューで作られたレディーキューに接続要求を出します。サスペンド状態なども定義可能です。
その他、セマフォなどの同期オブジェクトのウェイトキューへの接続や、待ち解除時のレディーキューへの再接続要求など、状態変更する為のステートマシンとして構成しております。後述しますがイベントフラグの機能はタスク状態に含めてしまっています。
また、今回オブジェクト内にタイムアウト機能も実装しています。RTOSでは時間待ちも出来ると便利なケースが多いのですが、カウントダウンしていって待ち解除すだけなので極めて簡単に実装でき、タイマキューもなく各タスクが独立に時間をカウントできます。これもZynqクラスのFPGAであればタスクの数だけ単純カウンタを持たせる程度であれば大きなインパクトにはならないと考えています。
あまり時間単位が細かくても不便なのでプリスケーラは設けていますが、PLロジックでの制御なのでその気になれば 例えば 100MHz で 10ns 単位の時間制御という細かい粒度での時間待ちも可能です。
ちなみにタスク優先度制御に関しては、どこかのキューに接続されているときの優先度変更時は、CPU側から一度取り外して再接続してもらうことを想定していますが、まだ実装していません(汗)。必要性が出たら考えようと思います。
セマフォ機能
今回はセマフォとしてカウンティングセマフォを実装しています。セマフォはそのカウント値を1として排他制御に用いたり、もっと大きなカウント値を用いて、割り込みパルス数をカウントしてその回数だけタスクを実行するなどの用途に使えます。
セマフォ内にはウェイトキューを備えており、優先度キューかFIFOキューかを選べるようにしています。セマフォ待ちのタスクはウェイトキューに接続され待ち状態となり、セマフォが獲得できると待ち解除されます。
今回、まだ実装していませんが、若干の調停回路の追加で、外部ハードウェアからカウントインクリメントするポートを付けることもそれほど難しいことでは無いと思います。
イベントフラグ機能
機能の半分はタスク側に持たせている部分もありますが、各タスクは独立に複数のbitをAND待ちやOR待ちが可能で、それぞれ条件が揃うと待ち解除されます。
イベントフラグはタスク毎に独立しているので排他制御も必要なく、容易にPL上のロジックからイベントフラグをセットすることができます。 これは従来であれば割り込みとしていて受けていた外部シグナルを受けるのに非常に便利です。
例えばDMAなどの完了待ちをするのに、従来であれば
- DMA完了割り込みハンドラ準備
- DMA起動
- フラグ待ち
- DMA完了割り込みでフラグセット
のような処理が必要だったところが
- DMA起動
- フラグ待ち
の2アクションで済んでしまいますし、余計なCPU処理も入らず応答性も速くなります。
CPUでのタスクスイッチ実装
CPUでのタスクスイッチ(コンテキストスイッチ)の実装はここなどにありますが非常にシンプルです。
コンテキストごとにスタック領域を確保しておき、利用するレジスタセットをスタックにpushしたあとに、RTOSコアから実行すべきタスクIDを読み出してスタックポインタを入れ替えてpopするだけです。
後は初期スタックの構築などいくつかの準備をするだけで準備完了となります。
CPUでのAPI実装
殆どのAPIはレジスタアクセスだけで出来るようにしていますので、殆ど特定アドレスの読み書きのラッパーのみと言った感じになります。
おわりに
多くのアルゴリズム開発において、演算種別や並列性において、PSに適した部分とPLに適した部分が混在するのはよくある話です。しかしここで特にエッジコンピューティングにおいては「ハードリアルタイム保証」という観点からマッピングの自由度が低下するケースが多々ありました。
実際、500~600MHzで動作してVFPも備えたCortex-R5においては、同じ性能をPLで出そうとすると困難なアルゴリズムも多数存在しますので、有効利用しない手はありません。
PSとPLワンチップに統合されたZynqMPのようなアーキテクチャの場合、この点においてより踏み込んだマッピングが可能になってくるのですが、その際、RTOS的な要素はとても重要になってきます。
RTOSのFPGA化が、よりPLとPSを密連携させたアーキテクチャの探索のカギになれば嬉しいと思います。
余談
今回、メモリマップドI/O的にレジスタアクセスをRTOSの操作にアサインしていますが、これはほとんどCPUの命令デコードと変わりません。
もしCPUとセットで設計する場合、例えば RISC-V とかなら、独自命令として追加していくと面白そうに思います。FPGAでCPUを構成する場合、レジスタファイルをブロックSRAMなどで構成すれば16スレッド分ぐらいのレジスタセットが出来てしまうので、コンテキストスイッチもロジック化出来てしまいそうです。
まあソフトコアCPUは、先に述べた「PSに適した部分とPLに適した部分が混在するアルゴのマッピング」に真っ向から反した話ではあるのですが、ハードマクロのCPUを持たない純粋なFPGAでの実装や、ASIC化も視野に入れた話とかだと面白い話になるのかなと考えてみたりしております。