はじめに
Ultra96V2(ZynqMP)は、PL(Programable Logic)とともに、APUにCortex-A53を4個、RPUにCortex-R5を2個搭載したエッジコンピューティングデバイスで、PLにI/Oロジックや演算ロジックをプログラムすることで様々な機器との接続や、一般的なCPU/GPUが苦手な複雑な演算を高性能に処理したりすることができます。
APUとRPUなどを含む、所謂普通のエッジコンピュータ部分をPSと呼びますが、PS と PL 間の通信には大きく2つの手段があります。
- 搭載されている LPDDR4-SDRAM を経由して通信する
- PL⇔PS間をつなぐAXI4インターフェースを用いて直接アクセスする
今回は後者にフォーカスをあてて計測を試みてみました。
GPGPUなどの一般的なアクセラレーションユニットは、基本的にはメモリを介して通信することが多いですので、プログラマブルロジックならではといった機能かと思います。
先の書いたように、PL(Programable Logic)は、外部ピンに繋がっており、デバイスとの接続ロジックもプログラム出来ますし、複雑な演算ロジックも組めます。
したがって
という、まだだれもやったことのないプログラミングに挑戦できるワクワクするような仕組みだったりします。
GPUプログラミングなどの「用意されたアーキテクチャの上でプログラミングする」のではなく、「自分で計算機アーキテクチャ自体自由に組み替えながらプログラミングしてしまう」という楽しさが、プログラマブルロジックを使ったプログラミングの醍醐味かと思います。
性能計測
さて、前置きはさておき、実際やってみた性能計測に触れていきます。 APU(Cortex-A53)はNEONもあり高性能なのですが、Linuxも搭載されており、キャッシュ制御など様々な制御のハードルが高かったので、今回は RPU(Cortex-R5) をメインに M_AXI_HPM0_LPD ポートを使った計測を行っております。
論理性能
まずは論理性能の確認です。
PL⇔PS間には最大で333MHまで許容可能な128bitのバスが何本か用意されています。ボードに搭載のLPDDR4-SDRAMと比べると以下の通りです。
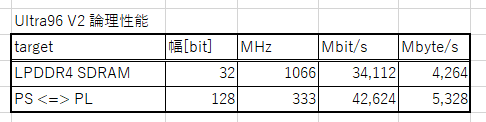
しかも、PL⇔PS間のインターフェースは Read と Write を同時に行えますので、1ポートで実質的には LPDDR4-SDRAM の2倍以上の帯域を持っていることになります。
ちなみに、LPDDR4 も PL も、6個あるCPUのアクセスを一手に引き受けることが可能なインターフェースなので CPU1個だけに対しては余裕のある性能と予想できます。
C言語で計測
では実際に PL にプログラムしたダミーコアを、long long 型(64bit) の128MByteの配列に見立てて RPUを1個だけ使ってアクセステストを実施しました。 キャッシュ設定をいろいろ弄れてしまうのがOSなしで自由に組み込みプログラミングできてしまうRPUのいいところです。
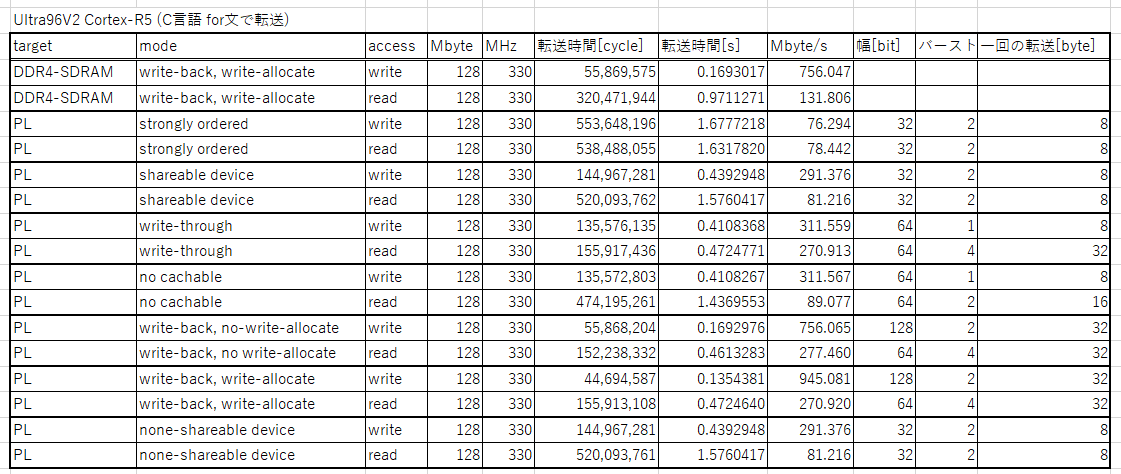
「write-back, write-allocate」という、まあ普通のキャッシュ設定時においては、LPDDR4 を超える性能が出ているようです。 特に、LPDDR4が外部チップにアクセスするのに対して、PLは同じチップ内で完結しておりますので read のレスポンスを得ることが速く、キャッシュミス時の性能低下は低いと思われます。
アセンブラで計測
ところで、PLはメモリではありませんので、キャッシュする意味合いはメモリほどはありません。 もちろんキャッシュという機構が、ある程度まとめてデータを取ってきてから細かくCPUに渡したり、細かい書き込みを溜めておいてまとめて書いたりしてくれるので1回のアクセス単位が大きくなり、アクセス効率が上がるとお言うのはあります。
一方で、先はC言語でアクセスしましたが、ARMには stm/ldm などといった、複数のレジスタを一括して読み書きするマシン語命令があります。 これを使えばキャッシュ無しでも性能が出るのではないかという事で行った実験が下記です。

キャッシュONの場合はアセンブラで書いても大きくは性能向上しませんでしたが、キャッシュ無しの方はこの方法で大幅に性能アップしています。
PLへのアクセスは専用のライブラリをアセンブラで書いてやれば十分な帯域でアクセスできそうですし、そうすれば貴重なキャッシュメモリをLPDDR4のアクセスにすべて割り当てられますので効率アップにも寄与しそうです。
まとめ
PSから LPDDR4 を経由して演算させる方法がうまくいったと仮定すると
- LPDDR4経由: PS → LPDDR4 → PL → LPDDR4 → PS
- PL直接: PS → PL → PS
という差になります。 LPDDR4 経由の場合、メモリの往復が2回発生します。一方で、PL直接の場合は1往復です。しかもreadとwriteは同時に転送できますので4倍の性能アップの上に、LPDDR4 を他のCPUに丸々解放できるといういいことずくめのことが起こります。
さらに外部デバイスから受け取ったデータをCPUで処理して表示する場合(例えばカメラ画像を加工してディスプレイに表示とか)、
- LPDDR4経由: カメラ → PL → LPDDR4 → PS → LPDDR4 → PL → ディスプレイ
- PL直接: カメラ → PL → PS → PL → ディスプレイ
などということも可能性としては出てくるわけです。
実際やろうとすると大変そうですが、それでもVGA(33MHz)ぐらいのピクセルクロックの画像ならラインバッファ+CPUで上記をやるようなシステムは成り立ちそうな気もします。
おまけ
今回の計測はPL側にILAという組み込みロジックアナライザを埋め込んでバスアクセスを観測することで行いました。
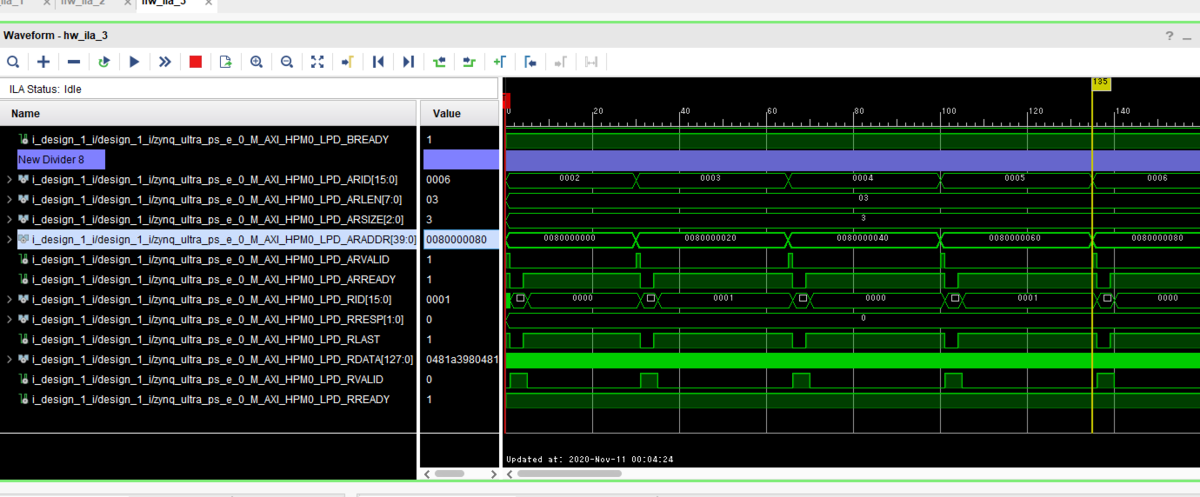
Tegra や Raspberry PI など、エッジコンピューティングデバイスは数あれど、「性能が出なくて困った」、なんて時の計測でバスアクセスが比較的簡単に観測できてしまうなんていうのがプログラマブルロジックの便利なところです。
さあみんなで始めよう、非ノイマン型プログラミング(笑)。