はじめに
少し前に、X(Twitter) にこんな絵を張り付けた。 ちょうど BitNet(b1.58) が盛り上がっていて、パラメータ効率の議論が起こっていたときだと思う。
忘れる前にもう少し書いておこうと思う。
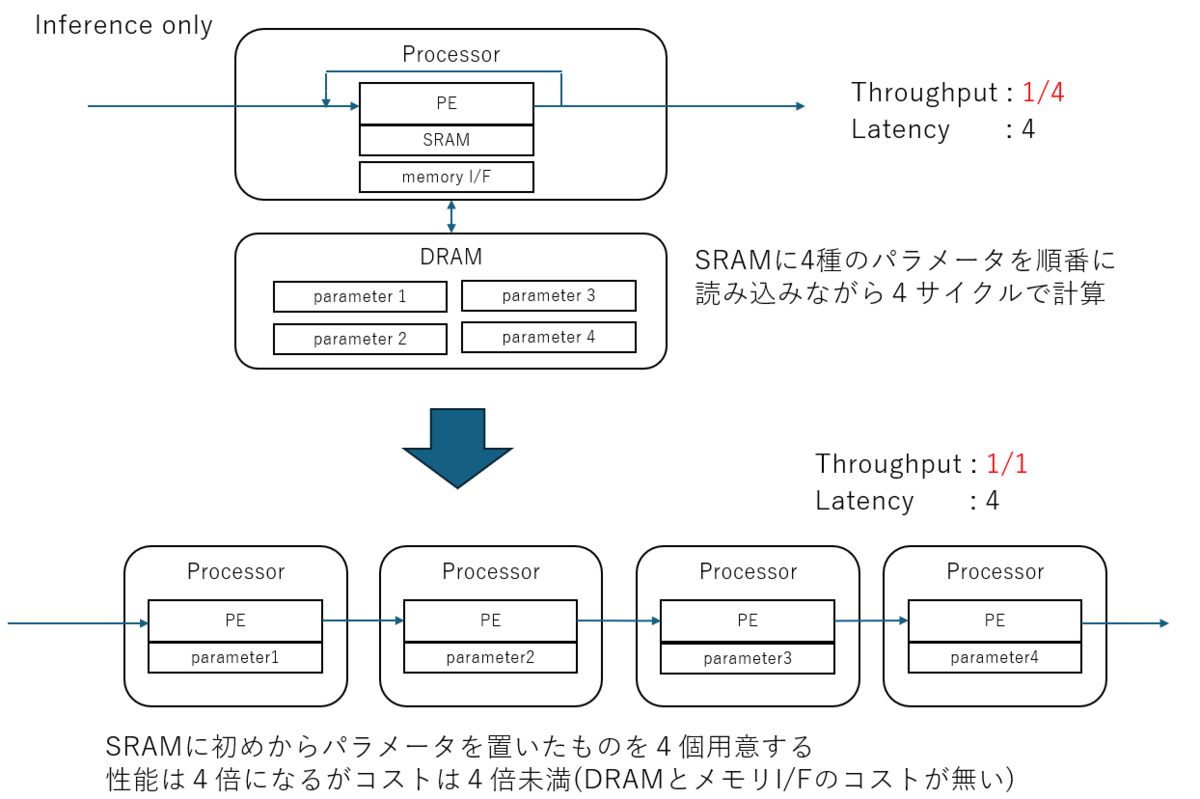
上の図では少なくとも DRAM などの外部メモリや、そこへ読み書きアクセスを行ってパラメータ入れ替えをする機構が要らなくなる分、お得であることは伝わると思う。 大量の演算器リソースと、それを埋め尽くす入力リソースが無いと成り立たないので GAFAM のような企業でないと難しいかもしれないが、確かにコスパのいい推論が出来るはずなのだ。
と言う話だったが、これには続きがある。
ここまでは LSI 開発をしてチップを作っても効果がある。が、FPGA だと更に パラメータごと合成する というメリットが発生するのだが、そこにはまだ十分触れられてなかった。
これがFPGAだとさらに嬉しい
これが FPGA の場合、さらに パラメータごと合成する メリットが出てくる。
どういうことか、ここでさらにちょっと具体的なパラメータを入れてみる。
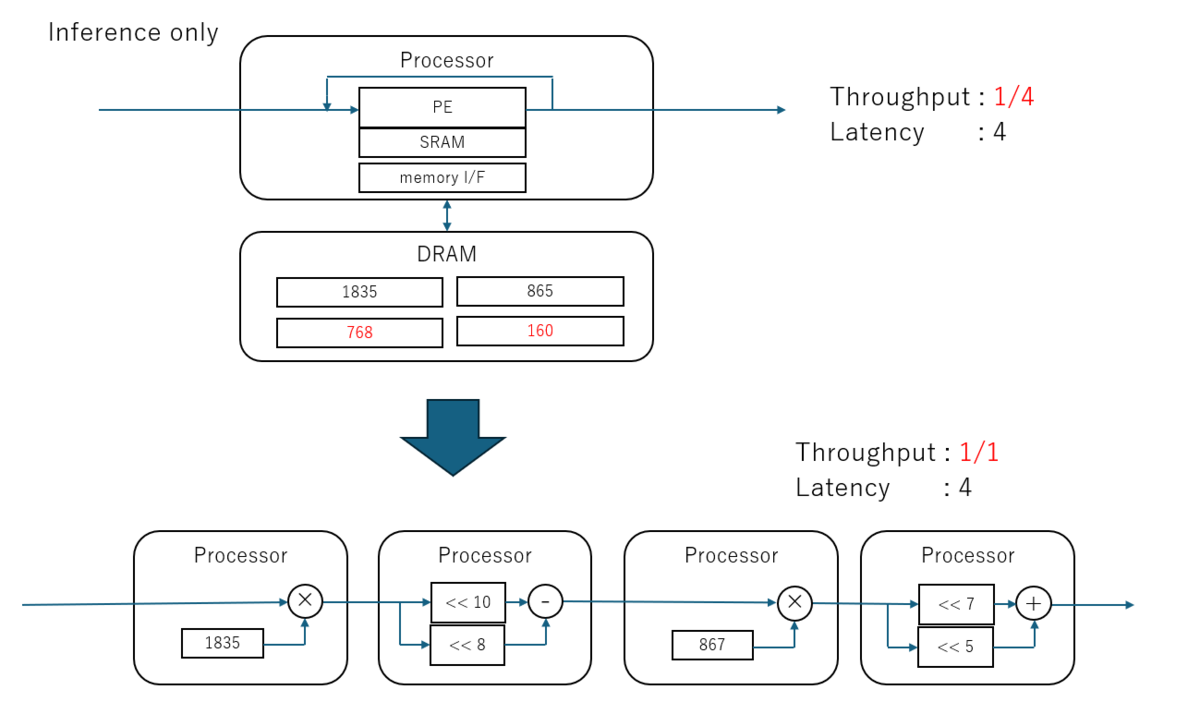
やや作為的ではあるが、例えば 768 は 1024 - 256 であるし、 160 は 128 + 32 であるから、乗算が減算や加算に置き換わる。
もっと極端にパラメータが 2 のべき乗なら接続をずらす(シフト)だけだし、0 なら演算回路ごと消えてしまう。
これがパラメータごと合成するという事だ。 LSI化する場合、どうしても変更可能な要素としてパラメータを可変にするので、どんなパラメータが来ても良いように乗算器はフルスペックで用意するしかない。 しかし、FPGAなどのリコンフィギャラブルだと、パラメータが変るたびにパラメータごと演算器を再合成できるのがメリットだ。
LUT-Net の場合は?
ちなみに拙作の LUT-Net はその究極形だと考えている。
なにしろ、乗算ではなく、LUT演算といいうものを学習させて、そのままLUTのテーブルをパラメータとして、合成と言う工程すら無きに等しい状態にしていますので、これは究極の パラメータごと合成 なのだ。
利用できるシーンは限定される
一見、書き換え可能なFPGAだからこそできる超効率の道にも見えるが、当然凄まじい制約がある。
パラメータごと合成する以上、回路規模以上のパラメータ数が使えない のである。 これは実質的にかなり小さいネットワークに対してしか使えないことを意味する。
加えて、非常に高いデータレートのコアが出来てしまう為、高帯域の入力需要が無いと帯域を使いきれないのでコスパのメリットが出なくなる。
しかし逆に言えば、コスパのいいFPGAに合成して収まる程度のパラメータ数の DL(Deep Lerning)推論で、且つ、十分な入力データがあれば極めてコスパが良くなる。
例えば MNIST などは DL の入門として扱うような今となってはシンプルなものだが、ではルールベースで判別プログラムを書けと言われても容易ではない。
目視で簡単に見つかりそうなヒビとか傷検出みたいなものでも、ルールベースだと案外難しかったりするのだ。
そういった DLとしては簡単だが、ルールベースは困難 という分野で役に立つ。例えば超安価なFPGAに高帯域のビデオで信号流し込むだけで、欠陥検知してくれるなどだと嬉しいシーンなどはあるのではないだろうか?
おわりに
今回は、リコンフィギャラブル故にできるパラメータごとの合成の可能性という FPGA のメリットに着目してみた。
パラメータを増やすことこそ正義のLLM全盛期に、小パラメータネットの効率を言っても見向きもされない面はあるのかもしれないが、ではLLM分野で勝てるのかと言うと、資本力が無いとそもそも参戦すらできない。こういうスキマ分野を考えてみるのも悪くはないと思う。
利用シーンは限られるものの、特に筆者は RaspPI カメラを 1000fps 駆動して遊ぶような人間なので、安価な高帯域データをあしらうのは大好きである。
なかなか、ビジネスに結びついていないところではあるのですが、そういう観点も面白いと思う。












